
컴퓨터는 텍스트를 이해할 수 없다. 따라서 텍스트를 숫자로 변환하는 텍스트 벡터화(Text Vectorization) 과정이 필요하다.
원-핫 인코딩
원-핫 인코딩 (One-Hot Encoding)은 문서에 등장하는 각 단어를 고유한 색인 값(index)으로 매핑한 후, 해당 색인 위치를 1로, 나머지는 0으로 표시하는 방식이다.
I like apples, I like bananas 라는 두 문장을 토큰화하고 매핑 테이블을 구하면 아래와 같다.
| Index | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| Word | I | like | apples | bananas |
이를 바탕으로 원-핫 인코딩을 진행하면 아래와 같다.
I like apples->[1, 1, 1, 0]I like bananas->[1, 1, 0, 1]
이러한 방법은 단어나 문장을 벡터 형태로 변환하기 쉽고 간단하다는 장점이 있지만, 벡터의 희소성 (Sparsity)이 크다는 단점이 있어 자칫 차원의 저주와 같은 문제에 빠질 수 있다.
빈도 벡터화
빈도 벡터화 (Count Vectorization)는 BOW를 만드는 방법이다. 먼저 BOW를 알고 넘어가자.
경제 뉴스에서는 경제 관련 단어가, 정치 뉴스에선 정치 관련 단어가 많이 나오듯, 문서의 내용과 연관성이 높은 단어가 자주 등장할 것이다. 이런 가설을 바탕으로 BOW, Bag of Words가 나왔다.
BOW는 단어들의 출현 빈도(frequency)에만 집중하는 텍스트 데이터의 수치화 표현 방법이다.
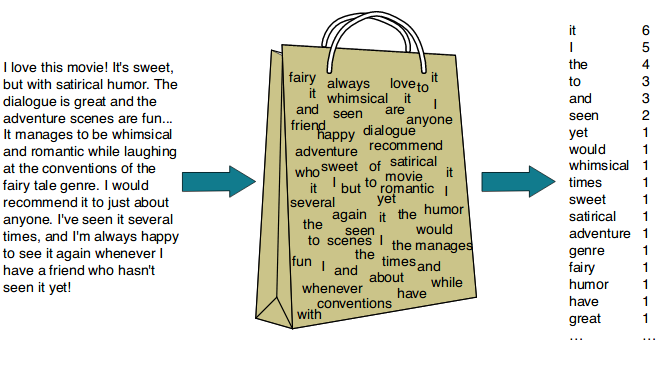
단어 피처에 값을 부여할 때, 각 문서에서 해당 단어가 나타나는 횟수를 부여하는 경우를 카운트 벡터화 또는 빈도 벡터화라고 한다.
I have an apple, do you have a banana? 라는 문장을 빈도 벡터화 하면 다음과 같다.
| |
| |
an는 2번, apple는 1번, do은 1번, have은 2번, orange는 1번, you는 1번 나왔다. 2글자 미만인 I는 제외되었다.
이와 같이, 단어의 빈도만 고려하기 때문에 an과 같은 관사가 중요하게 고려되었다. 따라서, CountVectorizer(stop_words=["the", "a", "an", "is", "not"]) 과 같이 불용어를 제거하고 사용하기도 한다.
하지만, 여러 문장에서 자주 사용되는 단어들을 모두 불용어로 지정하는 것은 한계가 있을 것이다.
TF-IDF
TF-IDF(Term Frequency-Inverse Document Frequency) 란 텍스트 문서에서 특정 단어의 중요도를 계산하는 방법으로, 문서 내에서 단어의 중요도를 평가하는 데 사용되는 통계적인 가중치를 의미한다.
즉, BOW에 가중치를 부여하는 것이다. TF-IDF의 식은 아래와 같다.
$$ \text{TF–IDF} = \text{TF}(t, d) \times \text{IDF}(t, d) $$
TF-IDF는 위와 같이 TF와 IDF의 곱이다. 먼저 TF에 대해 알아보자.
TF는 Term Frequency, 단어 빈도이다. 3개의 문서에서 movie라는 단어가 4번 등장했다면, 값은 4이다.
$$ \text{TF} = \text{count}(t, d) $$
IDF는 Inverse Document Frequency로, 전체 문서 수를 문서 빈도로 나눈 다음에 로그를 취한 값이다.
문서 빈도가 높을수록 해당 단어가 일반적인 단어일 것이다. 따라서 IDF는 문서 내에서 특정 단어가 얼마나 중요한지를 나타낸다.
| |
| |
이를 통해 문서마다 중요한 단어만 추출할 수 있으며, 벡터값을 활용해 문서 내 핵심 단어를 추출할 수 있다.
빈도 기반 벡터화는 문장의 순서나 문맥을 고려하지 않는다. 그러므로 문장 생성과 같이 순서가 중요한 작업에는 부적합하다. 또한, 벡터가 해당 문서 내의 중요도를 의미할 뿐, 벡터가 단어의 의미를 담고 있지는 않다.