
Word2Vec의 최적화
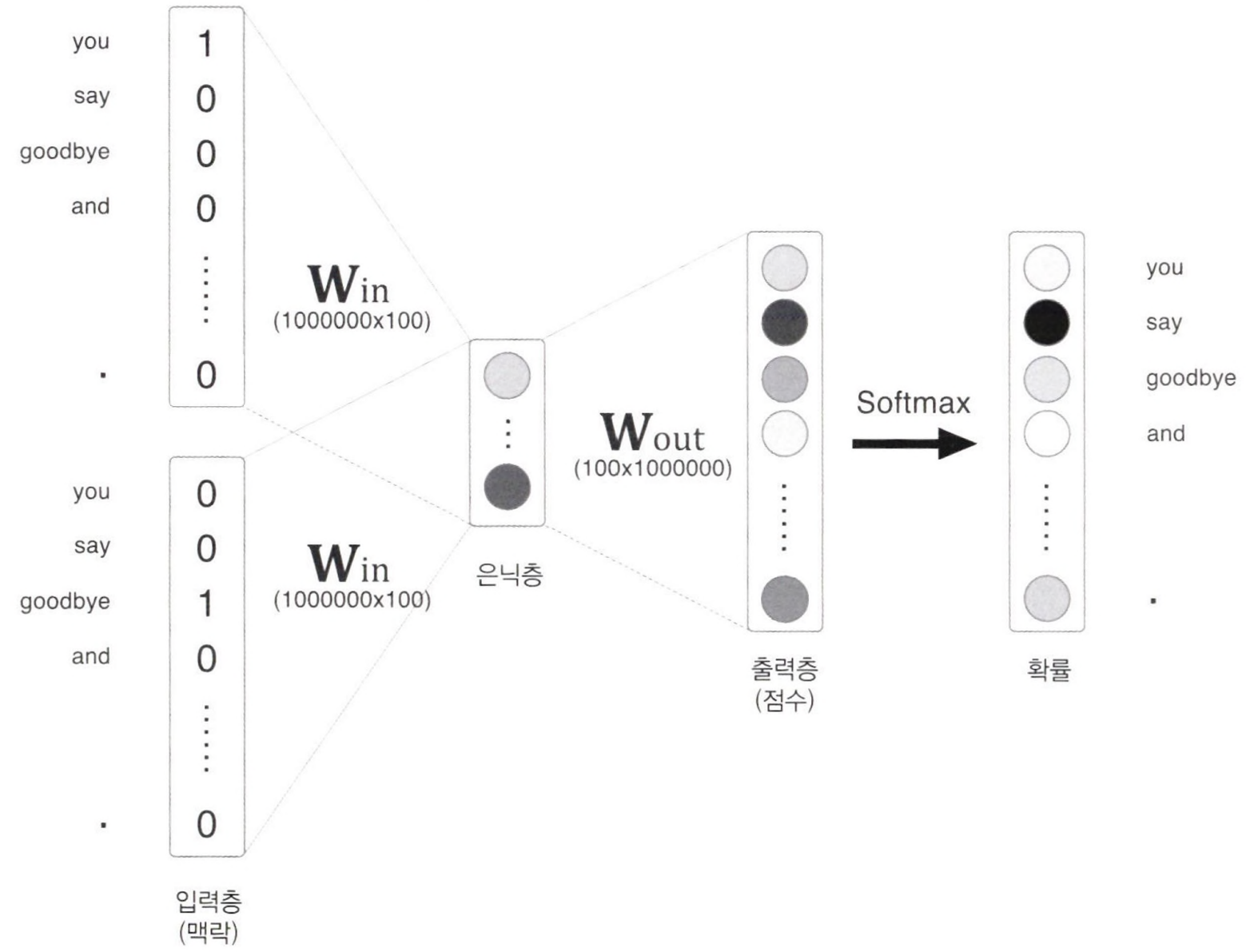
Word2Vec은 자연어 처리 분야에서 매우 중요한 도구로 자리 잡고 있다. 그러나 Word2Vec은 어휘의 양이 방대해질수록 계산량과 메모리 사용량이 커지는 문제를 가지고 있다. 이러한 문제를 해결하기 위하여 ‘임베딩(Embedding)’ 계층을 도입하고 ‘네거티브 샘플링(Negative Sampling)’ 기법을 적용하는 두 가지 주요 개선 방법을 살펴보자.
Embedding 계층
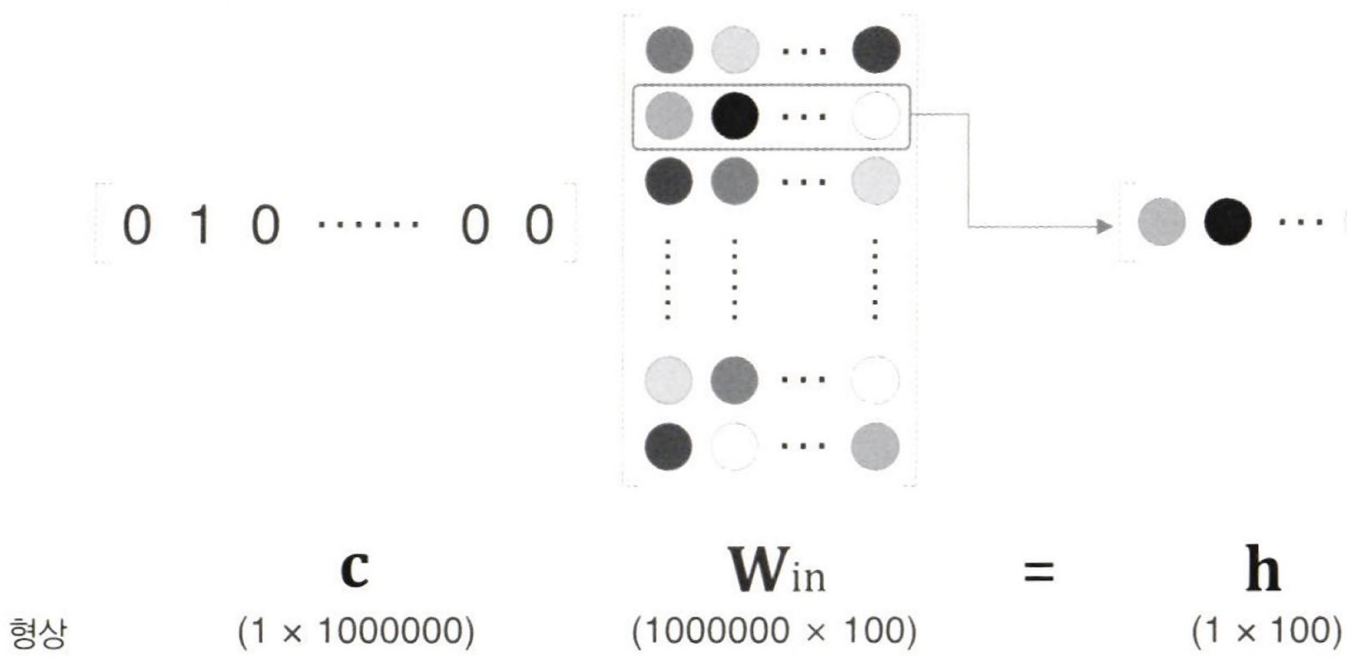
배경
전통적으로 단어를 표현하는 방법 중 하나는 원-핫 인코딩이다. 이 방법은 각 단어를 하나의 긴 벡터로 표현하며, 벡터의 크기는 어휘의 크기와 같다. 벡터에서 단어에 해당하는 위치는 1이고 나머지는 모두 0이다. 이 방식은 직관적이지만, 벡터가 대부분 0으로 채워지는 희소성 문제와 차원이 커질수록 계산 비효율성이 증가하는 문제를 가지고 있다.
예를 들어, 어휘 사전에 10,000개의 단어가 있다면, 각 단어는 10,000차원의 벡터로 표현된다. 이렇게 고차원 벡터와 가중치 행렬의 곱셈 계산은 많은 계산 자원을 소모한다.
임베딩 레이어는 각 단어를 고정된 크기의 밀집 벡터로 변환한다. 이 밀집 벡터는 단어의 의미를 수치적으로 포착할 수 있으며, 벡터의 각 요소는 연속된 값으로 이루어져 있다. 이로 인해 희소성 문제를 해결하고, 효율적인 계산이 가능해진다.
작동 원리
임베딩 레이어는 각 단어를 고유한 인덱스에 매핑하고, 이 인덱스를 사용하여 단어의 밀집 벡터를 찾는다. 이 밀집 벡터는 학습 가능한 파라미터로, 모델 학습 과정에서 최적화된다.
전통적인 원-핫 인코딩 방식은 단어의 인덱스에 해당하는 위치에만 1을 두고 나머지는 0으로 채워 계산을 수행한다. 이에 반해, 임베딩 레이어는 각 단어에 대한 밀집 벡터를 직접 참조하여 계산을 수행하기 때문에, 불필요한 계산을 크게 줄여준다.
구현 예시
| |
네거티브 샘플링 기법
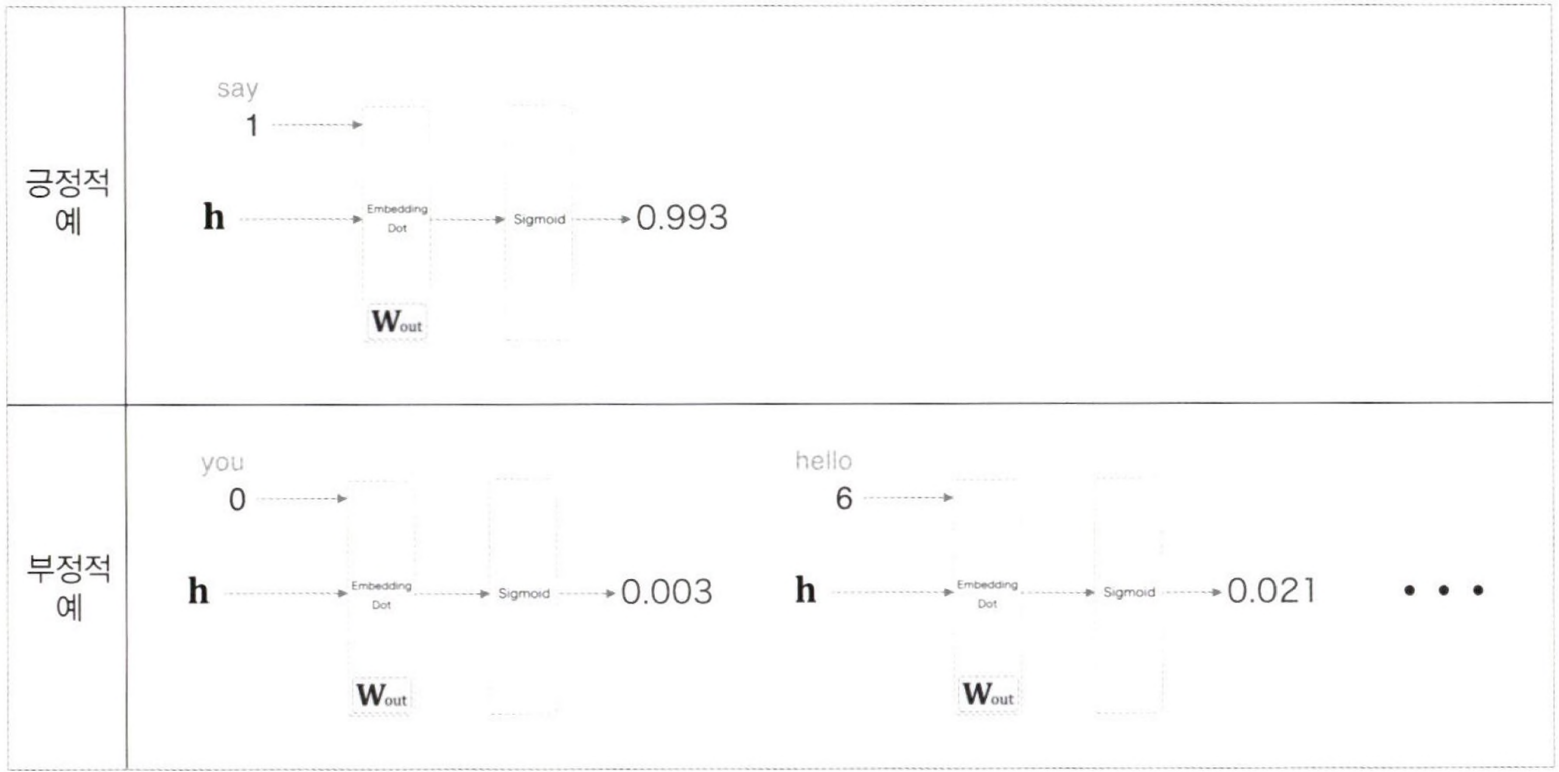
네거티브 샘플링은 다중 분류 문제를 이진 분류로 근사하여 계산량을 대폭 줄이는 기법이다. 이 기법은 특히 대규모 어휘를 다루는 자연어 처리에서 중요한 역할을 한다.
배경
Word2Vec과 같은 언어 모델은 단어의 의미를 벡터로 변환하여 수치화하는 과정을 수행한다. 이 과정에서 전체 어휘에 대한 예측을 수행하게 되면, 어휘의 크기가 커질수록 계산량이 매우 늘어나는 문제가 있다. 특히, Softmax 계층에서의 계산은 모든 어휘에 대해 수행되어야 하므로, 어휘 수에 비례하여 계산량이 급격히 증가한다. 네거티브 샘플링은 이러한 문제를 효과적으로 해결하는 방법으로 제안되었다.
다중 분류 문제의 이진 분류 근사
네거티브 샘플링의 핵심 아이디어는 다중 분류 문제를 이진 분류 문제로 근사하는 것이다. 전체 어휘에 대한 예측 대신, 모델이 특정 단어를 정답으로 예측하는지 여부만을 판단하게 한다. 즉, ‘이 단어가 맞는가? 아닌가?‘라는 간단한 질문에 답하는 형식으로 문제를 단순화한다.
긍정적 예와 부정적 예의 선택
긍정적 예(Positive Samples): 모델이 맞추어야 하는 실제 단어. 예를 들어 문맥이 “The cat sits on the” 일 때, 실제 다음 단어인 “mat” 이 긍정적 예가 된다.
부정적 예(Negative Samples): 무작위로 선택된 단어들로, 모델이 이 단어들을 정답으로 선택하지 않도록 학습한다. 이들은 긍정적 예와 구분되어야 할 대상들이다.
계산 효율성의 증가
네거티브 샘플링을 사용하면 모델이 전체 어휘에 대한 Softmax 계산을 수행할 필요가 없어진다. 대신, 긍정적 예에 대해서는 확률을 높이고, 선택된 부정적 예에 대해서는 확률을 낮추는 방식으로 학습이 이루어진다. 이 과정은 계산량을 현저히 줄여주며, 특히 어휘의 크기가 큰 경우에 매우 효과적이다.
구현 예시
| |
CBOW 모델 구현
이전 포스팅에서 구현했던 CBOW 모델에 Embedding과 Negative Sampling Loss 계층을 적용해 개선해 보자.
| |
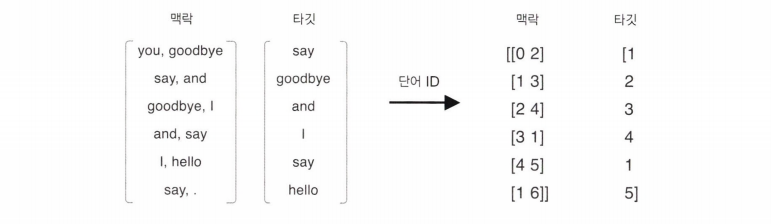
단어 ID의 배열이 contexts와 target의 예이다. 맥락은 2차원 배열이고 타겟은 1차원 배열이고, 이러한 데이터가 순전파에에 입력되는 것이다.
결론
임베딩 계층과 네거티브 샘플링 기법은 Word2Vec 모델의 계산량과 메모리 사용량을 현저하게 줄여주는 효과적인 방법이다. 특히, 대규모 어휘를 가진 말뭉치를 다루는 데 있어서 이러한 개선 방법은 필수적이다. 이를 통해 보다 빠르고 효율적으로 자연어 처리 모델을 학습이 가능하다.
Word2Vec은 자연어 처리에 중요한 역할을 하고 있다. 이것으로 단어들이 고정 길이의 벡터로 변환되며, 이렇게 변환된 단어 벡터는 비슷한 의미를 가진 단어들을 찾는 데 유용하게 사용된다. 또한, 단어의 분산 표현은 전이 학습에도 적용할 수 있는데, 이는 한 분야에서 획득한 지식을 다른 분야에 적용하는 것을 의미한다. 이를 통해 다양한 자연어 처리 문제에 효과적으로 접근할 수 있다.
자연어 처리 작업에서는 Word2Vec 모델이 주로 큰 말뭉치로 사전 학습된 상태에서 사용된다. 예를 들어, 텍스트 분류, 문서 클러스터링, 감정 분석 등의 작업에서 사전에 학습된 단어 벡터를 활용함으로써 작업의 성능을 향상시킬 수 있다. 이러한 방식은 자연어를 벡터로 변환함으로써 일반적인 머신러닝 기법(신경망, SVM 등등)을 자연어 처리 문제에 적용할 수 있게 해준다. 따라서 Word2Vec의 단어 분산 표현은 자연어 처리 분야에서 높은 정확도와 효율성을 제공하는 핵심적인 요소가 되고 있다.